| tags:ebpf linux network tc categories:Linux
Egress traffic distribution with eBPF
When working with networks types other than Ethernet bonding is often not supported or just with a reduced feature set. With eBPF one can reimplement simple distribution of outgoing traffic.
When I administered HPC
clusters we had Linux machines working as routers between multiple high performance networks.
In this particular case, they were routing traffic from multiple hundreds of compute nodes
which were connected via an Omnipath
(OPA) network to a Infiniband (IB) network wherein the storage resided.
The design used two Intel Omnipath cards with 100 GBit/s each and one Infiniband card with 200 GBit/s.
Traffic coming in from OPA was of course all leaving via IB interface
but the other way around was a bit more difficult.
The company who designed the system set up
policy based routing
to select routing tables for all incoming
traffic depending on the interface it was coming from
0: from all lookup local
32758: from all iif ib2 lookup 2
32759: from all iif ib1 lookup 1
32760: from all iif ib0 lookup 2
32761: from all iif ib0 lookup 1
32766: from all lookup main
32767: from all lookup default
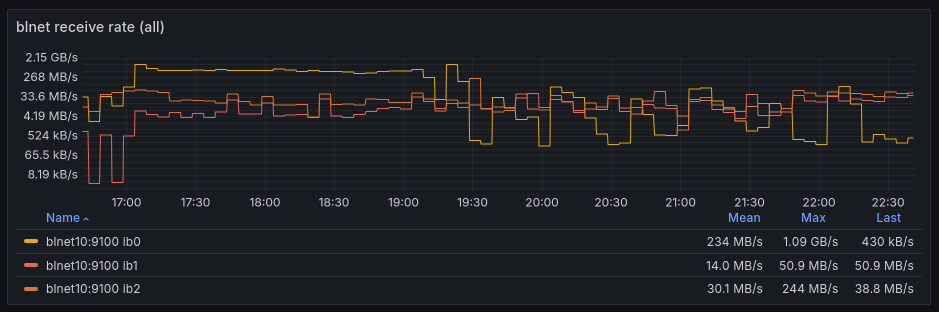
where ib0 is the Infinband interface and ib1 and ib2 are the OPA interfaces.
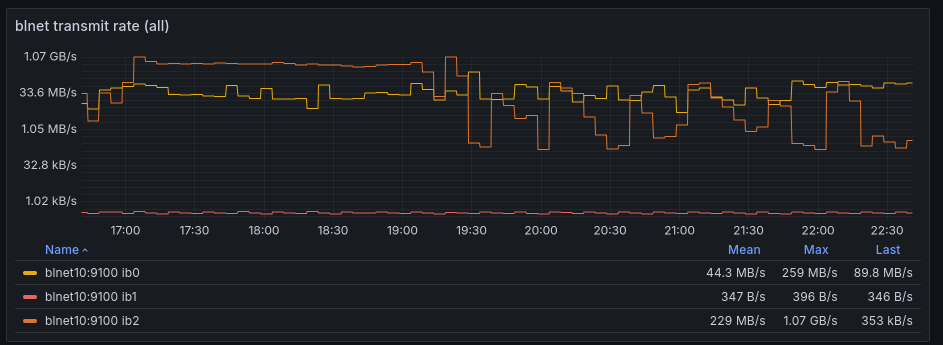
This obviously does forward all traffic flowing back from IB to OPA over just the one OPA link. The other is never used for production traffic, as it can be seen in the transmission graphs.
So I started to search for a way to solve this…
bonding
First idea that comes to mind is of course bonding (or teaming).
The operating company already told me that binding IB interfaces is not
the same as with Ethernet.
Particularly that the only bonding mode
which can be used is active-backup.
While this would increase fault tolerance it does not distribute traffic
across multiple interfaces.
A short research revealed that this is due to a limitation of the IPoIB driver which takes care of sending IP packets over Infiniband or OPA. Well I’m not going to touch that %)
netfilter / policy based routing
Next step would be to try to do this with iptables or ip rule.
Because netfilter was not used on those machines at all I didn’t look further into it.
Policy based routing was already in use so I searched a little but did not find any
dynamic solution.
Of course it would be possible to create subnet lists and assign them a specific interface.
This is good in a static environment and can even have some advantages when one knows the network topology.
However it does support a dynamic round robin solution.
Possibly you can build something similar with iptables and fwmarks but as far as I know it also boils down maintaining subnet lists.
eBPF as usual
eBPFs XDP is also not feasible because the TCP traffic changes from IB to OPA during routing. So it has to pass the Linux network stack to get packaged into a OPA frame. Also XDP work only on ingress traffic. This is where I learned that it is also possible to attach eBPF programs to traffic control (tc) filters. Although tc itself cannot change a packets outgoing interface eBPF can! And with tc on the other have it is possible to select only egress packets.
I found this blogpost which gives a good example about how to use eBPF in combination with tc.
Eventually I decided to adapt this and it turns out that it is pretty easy. Like with for example a XDP loadbalancer one needs to hash the parameters of the traffic flow and map the result to a interface decision. I tried the most simple implementation which just takes source and destination IP address and changes the interface or not.
// We select some stable parts of the IP header to keep hashing
// constant for each flow
struct {
__u32 src_ip;
__u32 dst_ip;
// HINT: ports or protocols could be added here
} flow_params = {bpf_ntohl(ipv4->saddr), bpf_ntohl(ipv4->daddr)};
// Select outgoing interface based on flow hash
__u32 key = xxhash32(&flow_params, sizeof(flow_params), 0) % 2;
bpf_printk("redirect: flow based key: %d\n", key);
if (key != 0) {
bpf_printk("redirect: performing redirect\n");
ret = bpf_redirect(TARGET_INTF, 0);
} else {
bpf_printk("redirect: NOT performing redirect\n");
}
return ret;
The full code is available on github.com/benibr/ebpf_ib. This example of course uses veth interfaces instead of infiniband since they are easy to test with.
Although this is of course not production ready it surprisingly works as expected as the kernel trace file shows:
nc-217522 [011] bNs2. 10795.081379: bpf_trace_printk: ---------------<BEGIN>---------------
nc-217522 [011] bNs2. 10795.081396: bpf_trace_printk: redirect: checking header for IPv4 proto. result: 800
nc-217522 [011] bNs2. 10795.081398: bpf_trace_printk: redirect: destination address 10.0.2.11
nc-217522 [011] bNs2. 10795.081401: bpf_trace_printk: redirect: NOT performing redirect
nc-217522 [011] bNs2. 10795.081402: bpf_trace_printk: redirect: result: 0
nc-217522 [011] bNs2. 10795.081404: bpf_trace_printk: ---------------<END>---------------
nc-217540 [011] bNs2. 10928.898478: bpf_trace_printk: ---------------<BEGIN>---------------
nc-217540 [011] bNs2. 10928.898494: bpf_trace_printk: redirect: checking header for IPv4 proto. result: 800
nc-217540 [011] bNs2. 10928.898495: bpf_trace_printk: redirect: destination address 10.0.2.40
nc-217540 [011] bNs2. 10928.898498: bpf_trace_printk: redirect: performing redirect
nc-217540 [011] bNs2. 10928.898500: bpf_trace_printk: redirect: result: 7
nc-217540 [011] bNs2. 10928.898501: bpf_trace_printk: ---------------<END>---------------
and tcpdump shows us that the router actually sends packets on different interfaces after the redirect:
19:02:52.343987 veth1@2 In IP 10.0.1.10.36475 > 10.0.2.11.7777: UDP, length 1
19:02:52.344081 veth2@1 Out IP 10.0.1.10.36475 > 10.0.2.11.7777: UDP, length 1
19:05:47.962493 veth1@2 In IP 10.0.1.10.52569 > 10.0.2.40.7777: UDP, length 1
19:05:47.962571 veth22@1 Out IP 10.0.1.10.52569 > 10.0.2.40.7777: UDP, length 1
In the repository there is also a Makefile which automatically sets up a testing enviroment if you wanna try it out.
Further reading
- https://ebpf.hamza-megahed.com/docs/chapter4/3-tc/
- https://qmonnet.github.io/whirl-offload/2020/04/11/tc-bpf-direct-action/
- https://medium.com/@fedepaol/ebpf-tc-filters-for-egress-traffic-b11cd0234a52
- https://eunomia.dev/tutorials/20-tc/
Appendix: ECMP Routing
While this was very interesting exercise, I later discovered though a colleague that the same
outgoing interface distribution is possible via ECMP
routing.
The clue here is, that the device (dev) is an attribute of the nexthop not the route itself so it’s easily
configurable with:
ip route add 10.0.0.0/16 nexthop dev ib1 nexthop dev ib2
and looks like this when running
[root@router1 ~]# ip r
10.246.0.0/16
nexthop dev ib1 weight 1
nexthop dev ib2 weight 1